|
Содержание:
- Введение
- Учебная задача
- Типы простых структур данных в VBA
- Методика тестирования
- Описание структур
- Структура DA1S
- Структура DA2S
- Структура DA2V
- Структура CA2V
- Структура A2A2V
- Структура A2A2A1V
- Структура A1UU
- Структура DDA1V
- Структура DDC
- Сравнительный анализ
- Файл проекта
- Итоговые рекомендации
ВВЕДЕНИЕ
В процессе решения практических задач на языке программирования VBA неизбежно возникает потребность размещать в памяти компьютера структуры данных, обращаться к ним, манипулировать ими. В целом VBA справляется с этой задачей хорошо. За исключением традиционных претензий к VB по поводу отсутствия указателей и средств прямого управления памятью, отсутствие которых обусловлено тем, что создатели языка намеренно хотели оградить программиста от подобной активности с целью роста продуктивности работы (среда берёт на себя все мелкие нюансы управления памятью в процессе объявления и использования структур), в остальном имеющиеся в VBA стредства вполне адекватны ожиданиям.
Основная причина, которая вынуждает VBA программиста размещать данные в оперативной памяти, а, скажем, не в таблицах Excel, - это необходимость обрабатывать большие объёмы информации с максимально возможной скоростью. Объекты, типа Range не могут обеспечить необходимой скорости в виду своей сложности и громоздкости. Любая операция с ячейкой рабочего листа занимает больше времени, чем операция с переменной в памяти. В виду этого, VBA программист должен уметь проектировать структуры данных, знать средства, которыми для этого располагает язык и знать слабые и сильные стороны разных подходов к созданию структур.
▲ вверх
УЧЕБНАЯ ЗАДАЧА
В этом исследовании мы рассмотрим 9 разных способов реализации одной единственной структуры данных, измерим производительность, которую система демонстрирует с этими реализациями, выберем победителя. Нам необходимо реализовать следующую модельную структуру: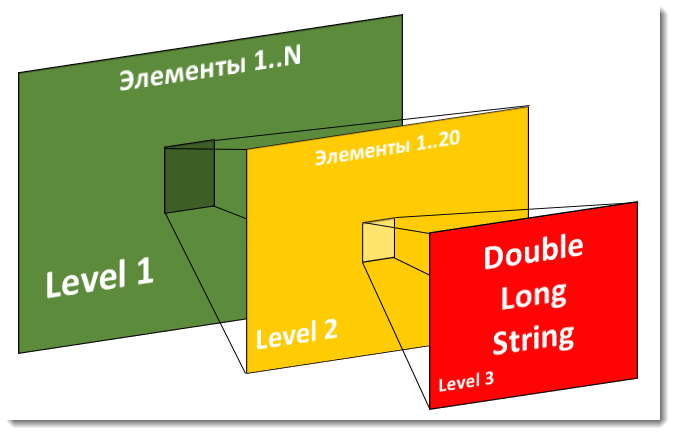
То есть у нас есть массив из N элементов (N считается неизвестным), каждый из которых в свою очередь является массивом из M элементов (M фиксировано и у нас =20), а те делятся ещё на 3 части с типами: double, long и string. Всего N*20*3 конечных элемента. Для доступа к массиву на первом уровне используются строковые ключи длиной 10 символов, для доступа к элементам массива на втором уровне используются ключи длиной 5 символов. Длина строки на третьем уровне 20 символов.
▲ вверх
ТИПЫ ПРОСТЫХ СТРУКТУР ДАННЫХ В VBA
|
Структура |
Описание |
|
Строка с разделителями (String with delimeters) |
Любая строка может служить контейнером для необходимого количества переменных строкового или числовых типов. Например, строка "ABCD123;123.45;789;" содержит в себе 4 элемента: строка ABCD123, вещественное число 123.45, целое число 789 и пустую строку. Работать с таким контейнером довольно хлопотно, но в то же время и ничего сложного. |
|
Фиксированный массив (Fixed array) |
Массив, как известно, это последовательность определенного количества однотипных элементов. В случае фиксированного массива, количество элементов известно уже на этапе объявления массива. В качестве элементов массива может быть что угодно: числа, строки, логический тип, дата-время, пользовательский тип, а также тип variant, что допускает в качестве элементов и другие массивы или объекты. |
|
Динамический массив (Dynamic array) |
Массив, для которого справедливо всё то, что сказано по поводу фиксированного массива, за исключением того, что количество его элементов может меняться в процессе исполнения программы. Для этого существует специальный оператор ReDim. Надо сказать, что это очень удобно и полезно, так как в большинстве случаев программист не может знать размеры необходимого ему массива, а объявлять огромные фиксированные массивы ужасный моветон. |
|
Пользовательский тип данных (User Data Type) |
Этот тип позволяет объявить контейнер, который будет иметь внутреннюю структуру. Тип напоминает запись базы данных (например, в Pascal такой тип так и называется - record). Данный тип данных позволяет разложить всё по полочкам. Он удобен и интуитивно понятен. |
|
Коллекция (Collection) |
Это объектный тип. Позволяет создать коллецию элементов. Каждому элементу во время добавления в коллекцию можно поставить в соответствие ключ (key), по которому потом удобно осуществлять доступ к самомму элементу (item). В целом полезен, если бы не было альтернативы в виде типа Dictionary, который перекрывает возможности Collection и по функционалу и по быстродействию. В качестве item (полезной нагрузки) допускает всё что угодно, кроме пользовательского типа. |
|
Словарь (Dictionary) |
Тоже объектный тип. Умеет всё то же, что и Collection, и дополнительно:
- Имеет метод Exists для определения наличия ключа в коллекции
- Может различать регистр в строковых ключах
- При доступе к элементам использует метод бинарного поиска, что сильно ускоряет перебор элементов и их поиск. Dictionary так же, как и Collection не работает с UDT, что достаточно досадно и нелогично.
|
|
Класс (Class) |
Чтобы подружить некое подобие UDT со словарями и коллекциями, применяют класс. Понятие класса слишком обширное, чтобы на этом останавливаться, тем более, что мы его применяем для предельно узкой задачи - заменить UDT объектным типом. |
▲ вверх
МЕТОДИКА ТЕСТИРОВАНИЯ
У нас подготовлено 9 VBA функций с именами: DA1S(), DA2S() и т.д., которые реализуют тестирование соответствующих структур. Под тестированием понимается полное заполнение структуры специально подготовленными данными. Данные одинаковы для всех алгоритмов. Далее осуществляется полный перебор структуры, но не последовательный, а по случайным ключам. Время измеряется и логируется. Процесс повторяется для всех алгоритмов с разным количеством элементов N уровня L1. Начинаем от N=1000, заканчиваем на N=70000.
▲ вверх
ОПИСАНИЕ СТРУКТУР
- Структура DA1S
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 |
For i = LBound(arrL1) To UBound(arrL1)
ReDim arrTemp(ArraySizeL2) As String
For j = LBound(arrL2) To UBound(arrL2)
arrTemp(j) = arrL2(j) & vbTab & arrDouble(j) & vbTab & arrLong(j) & vbTab & arrString(j)
Next
objRoot.Add arrL1(i), arrTemp
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
For k = LBound(arrFindL2) To UBound(arrFindL2)
strTemp = objRoot(arrFindL1(i))(k)
If Left$(strTemp, Key_L2_Length) = arrFindL2(j) Then
arrVariant = Split(strTemp, vbTab)
arrTargetDouble(j) = CDbl(arrVariant(1))
arrTargetLong(j) = CLng(arrVariant(2))
arrTargetString(j) = CStr(arrVariant(3))
Control = Control + arrTargetLong(j)
Exit For
End If
Next
Next
Next | |
|
Описание |
На первом уровне используем Dictionary, на втором - одномерный массив с элементами типа String. И ключи второго уровня, и переменные третьего - всё упаковывается в текстовую строку с разделителями. |
|
Преимущества |
Один из лучших алгоритмов с точки зрения экономии памяти. |
|
Недостатки |
Недостатков хватает. Операции со строками (упаковка, распаковка, преобразование типов) занимают массу времени. Опять же для поиска на L2 приходится распаковывать в среднем 9 лишних строк, чтобы найти нужную. Это всё обуславливает чуть ли не самое худшее время работы. |
▲ вверх
- Структура DA2S
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 |
For i = LBound(arrL1) To UBound(arrL1)
ReDim arrTemp(ArraySizeL2, 1) As String
For j = LBound(arrL2) To UBound(arrL2)
arrTemp(j, 0) = arrL2(j)
arrTemp(j, 1) = arrDouble(j) & vbTab & arrLong(j) & vbTab & arrString(j)
Next
QuickSort_D2_Variant arrTemp
objRoot.Add arrL1(i), arrTemp
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
If BinaryMatchStringD2(arrFindL2(j), objRoot(arrFindL1(i)), k) Then
arrVariant = Split(objRoot(arrFindL1(i))(k, 1), vbTab)
arrTargetDouble(k) = CDbl(arrVariant(0))
arrTargetLong(k) = CLng(arrVariant(1))
arrTargetString(k) = CStr(arrVariant(2))
Control = Control + arrTargetLong(k)
End If
Next
Next | |
|
Описание |
Level 1 - Dictionary, Level 2 - двумерный массив M x 2 строковых элементов, Level 3 - упакованная строка с разделителями. |
|
Преимущества |
DA2S потребляет памяти не сильно больше, чем его младший брат - DA1S, однако, в сравнении с ним серьёзно, более чем в 2 раза, повысилась скорость, так как теперь поиск на втором уровне осуществляется при помощи двоичного поиска и ключ больше не хранится в упакованной строке. Надо сказать, что все массивы на уровнях L1 и L2 я сортирую (Sub QuickSort_D2_Variant), а затем использую процедуру двоичного поиска (Function BinaryMatchStringD2). Это спорно при небольших числах M (количество элементов на уровне 2, у нас тут сейчас 20), но при росте этого числа алгоритм будет на этом экономить драгоценное время. Спорно из-за того, что затраты времени на сортировку могут не окупиться при небольшом количестве элементов в массиве. |
|
Недостатки |
Ярковыраженных недостатков нет, однако, код выглядит достаточно громоздко. |
▲ вверх
- Структура DA2V
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 |
For i = LBound(arrL1) To UBound(arrL1)
ReDim arrTemp(ArraySizeL2, 3)
For j = LBound(arrL2) To UBound(arrL2)
arrTemp(j, 0) = arrL2(j)
arrTemp(j, 1) = arrDouble(j)
arrTemp(j, 2) = arrLong(j)
arrTemp(j, 3) = arrString(j)
Next
QuickSort_D2_Variant arrTemp
objRoot.Add arrL1(i), arrTemp
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
If BinaryMatchStringD2(arrFindL2(j), objRoot(arrFindL1(i)), k) Then
arrTargetDouble(j) = objRoot(arrFindL1(i))(k, 1)
arrTargetLong(j) = objRoot(arrFindL1(i))(k, 2)
arrTargetString(j) = objRoot(arrFindL1(i))(k, 3)
Control = Control + arrTargetLong(j)
End If
Next
Next | |
|
Описание |
Ещё одна ветка развития DA1S. В этой версии структуры мы избавились от упакованной строки. L1 - словарь, L2 - массив с размерами M x 4 элементов с типом Variant. |
|
Преимущества |
Данная структура незначительно быстрее DA1S. Каждая переменная - в своей коробочке. |
|
Недостатки |
Памяти структура потребляет значительно больше, чем DA1S, а вот прирост в производительности достигнут совсем незначительный. Это происходит из-за того, что тип Variant занимает много места в памяти и обрабатывается существенно медленнее. DA2V гораздо медленнее, чем DA2S. |
▲ вверх
- Структура CA2V
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 |
For i = LBound(arrL1) To UBound(arrL1)
ReDim arrTemp(ArraySizeL2, 3)
For j = LBound(arrL2) To UBound(arrL2)
arrTemp(j, 0) = arrL2(j)
arrTemp(j, 1) = arrDouble(j)
arrTemp(j, 2) = arrLong(j)
arrTemp(j, 3) = arrString(j)
Next
QuickSort_D2_Variant arrTemp
objRoot.Add arrTemp, arrL1(i)
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
If BinaryMatchStringD2(arrFindL2(j), objRoot.Item(arrFindL1(i)), k) Then
arrTargetDouble(j) = objRoot.Item(arrFindL1(i))(k, 1)
arrTargetLong(j) = objRoot.Item(arrFindL1(i))(k, 2)
arrTargetString(j) = objRoot.Item(arrFindL1(i))(k, 3)
Control = Control + arrTargetLong(j)
End If
Next
Next | |
|
Описание |
На L1 у нас - коллекция, далее двумерный массив размерностью M x 4 элементов типа Variant. По-сути, это тоже самое, что и DA2V, но вместо словаря использована коллекция. Зная, что коллекция медленнее словаря, я не стал плодить множество вариантов структур, использующих коллекции, а добавил лишь эту, чтобы мы смогли наглядно убедиться в этом. |
|
Преимущества |
Преимуществ в сравнении с DA2V нет никаких. |
|
Недостатки |
Медленнее, чем тоже самое, но со словарём. Однако, медленнее на проценты (около 7%), а не в разы. В общем же зачёте скорость очень плохая - третья с конца. Код выглядит довольно громоздко. |
▲ вверх
- Структура A2A2V
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 |
ReDim arrTempL1(UBound(arrL1), 1)
For i = LBound(arrL1) To UBound(arrL1)
arrTempL1(i, 0) = arrL1(i)
ReDim arrTempL2(ArraySizeL2, 3)
For j = LBound(arrL2) To UBound(arrL2)
arrTempL2(j, 0) = arrL2(j)
arrTempL2(j, 1) = arrDouble(j)
arrTempL2(j, 2) = arrLong(j)
arrTempL2(j, 3) = arrString(j)
Next
QuickSort_D2_Variant arrTempL2
arrTempL1(i, 1) = arrTempL2
Next
QuickSort_D2_Variant arrTempL1
For i = LBound(arrFindL1) To UBound(arrFindL1)
If BinaryMatchStringD2(arrFindL1(i), arrTempL1, k) Then
For j = LBound(arrFindL2) To UBound(arrFindL2)
If BinaryMatchStringD2(arrFindL2(j), arrTempL1(k, 1), m) Then
arrTargetDouble(j) = arrTempL1(k, 1)(m, 1)
arrTargetLong(j) = arrTempL1(k, 1)(m, 2)
arrTargetString(j) = arrTempL1(k, 1)(m, 3)
Control = Control + arrTargetLong(j)
End If
Next
End If
Next | |
|
Описание |
Это уже знакомый нам DA2V или CA2V, но вместо словаря/коллекции тут применён массив размерностью N x 2 с типом элементов Variant, так как в половине элементов этого массива должны храниться другие массивы. |
|
Преимущества |
Данная структура демонстрирует отменную производительность (третий результат), что порождает во мне сомнения (сравнивая с DA2V), а так ли уж эффективно ищет Dictionary, если двоичный поиск, реализованный на VBA мною, его с лёгкостью обходит? И есть ли там вообще двоичный поиск... и, не должен ли я самостоятельно позаботиться, чтобы элементы Dictionary были отсортированы, чтобы двоичный поиск заработал... Это вопросы для будущих исследований. |
|
Недостатки |
Код стал совсем нелаконичным. |
▲ вверх
- Структура A2A2A1V
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 |
ReDim arrTempL1(UBound(arrL1), 1)
For i = LBound(arrL1) To UBound(arrL1)
arrTempL1(i, 0) = arrL1(i)
ReDim arrTempL2(ArraySizeL2, 1)
For j = LBound(arrL2) To UBound(arrL2)
arrTempL2(j, 0) = arrL2(j)
ReDim arrTempL3(2)
arrTempL3(0) = arrDouble(j)
arrTempL3(1) = arrLong(j)
arrTempL3(2) = arrString(j)
arrTempL2(j, 1) = arrTempL3
Next
QuickSort_D2_Variant arrTempL2
arrTempL1(i, 1) = arrTempL2
Next
QuickSort_D2_Variant arrTempL1
For i = LBound(arrFindL1) To UBound(arrFindL1)
If BinaryMatchStringD2(arrFindL1(i), arrTempL1, k) Then
For j = LBound(arrFindL2) To UBound(arrFindL2)
If BinaryMatchStringD2(arrFindL2(j), arrTempL1(k, 1), m) Then
arrTargetDouble(j) = arrTempL1(k, 1)(m, 1)(0)
arrTargetLong(j) = arrTempL1(k, 1)(m, 1)(1)
arrTargetString(j) = arrTempL1(k, 1)(m, 1)(2)
Control = Control + arrTargetLong(j)
End If
Next
End If
Next | |
|
Описание |
Довольно экзотическая реализация структуры. L1 - массив из N x 2 элементов типа Variant, L2 - массив из M x 2 элементов типа Variant, L3 - массив из 3-х элементов типа Variant. |
|
Преимущества |
Рекордсмен по экономии памяти. |
|
Недостатки |
В коде чёрт ногу сломит - многоэтажные ссылки (смотрите, например, строки кода 22-24). Хорошей скоростью похвастаться не может - середнячок. |
▲ вверх
- Структура A1UU
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 |
ReDim arrTemp(UBound(arrL1)) As externalUDT
For i = LBound(arrL1) To UBound(arrL1)
arrTemp(i).key = arrL1(i)
For j = LBound(arrL2) To UBound(arrL2)
arrTemp(i).arr(j).key = arrL2(j)
arrTemp(i).arr(j).varDouble = arrDouble(j)
arrTemp(i).arr(j).varLong = arrLong(j)
arrTemp(i).arr(j).varString = arrString(j)
Next
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For k = LBound(arrFindL1) To UBound(arrFindL1)
If arrTemp(k).key = arrFindL1(i) Then
ii = k
Exit For
End If
Next
For j = LBound(arrFindL2) To UBound(arrFindL2)
For k = LBound(arrFindL2) To UBound(arrFindL2)
If arrTemp(ii).arr(k).key = arrFindL2(j) Then
jj = k
Exit For
End If
Next
arrTargetDouble(j) = arrTemp(ii).arr(jj).varDouble
arrTargetLong(j) = arrTemp(ii).arr(jj).varLong
arrTargetString(j) = arrTemp(ii).arr(jj).varString
Control = Control + arrTargetLong(j)
Next
Next | |
|
Описание |
Интересная структура. Построена на пользовательском типе (UDT), да не простом, а вложенном, то есть один UDT, является составной частью другого. На первом уровне одномерный массив из N элементов с типом externalUDT. Вот как описывается этот тип:
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13 |
Type internalUDT ' структура для A1UU
key As String
varDouble As Double
varLong As Long
varString As String
End Type
Type externalUDT ' структура для A1UU
key As String
arr(ArraySizeL2) As internalUDT
End Type
]]>
Как видите, массив L2 создан внутри структуры UDT. | |
|
Преимущества |
A1UU демонстрирует отличную производительность при малом количестве элементов N. И я думаю, что будь реализована для UDT сортировка и линейный поиск, то это могло бы быть чёткое третье место, а то и повыше. |
|
Недостатки |
До 5000 элементов на L1 она стабильно демонстрирует третий результат скорости, но с ростом элементов скорость стремительно деградирует и к 70000 эта структура подходит с худшим результатом и до ближайшего соседа по несчастью - разрыв в три сотни процентов. Это безусловно связано с тем, что я для столь сложной структуры не реализовал линейный поиск, так как имеющиеся функции надо было бы переписывать чуть менее, чем полностью. Поэтому, кстати, и код выглядит ужасно. |
▲ вверх
- Структура DDA1V
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 |
For i = LBound(arrL1) To UBound(arrL1)
For j = LBound(arrL2) To UBound(arrL2)
ReDim arrTemp(2)
arrTemp(0) = arrDouble(j)
arrTemp(1) = arrLong(j)
arrTemp(2) = arrString(j)
InsertedDic_Add objRoot, arrL1(i), arrL2(j), arrTemp
Next
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
arrTemp = InsertedDic_Get(objRoot, arrFindL1(i), arrFindL2(j))
arrTargetDouble(j) = arrTemp(0)
arrTargetLong(j) = arrTemp(1)
arrTargetString(j) = arrTemp(2)
Control = Control + arrTargetLong(j)
Next
Next | |
|
Описание |
Это наш фаворит. Первые два уровня - словари. То есть словарь первого уровня в качестве своих items имеет объекты словарей второго уровня. И всего создаётся N+1 объектов типа Dictionary. |
|
Преимущества |
Лучший результат по скорости! За счёт подпрограмм InsertedDic_Add и InsertedDic_Get код выглядит чисто, лаконично и опрятно. Ничего лишнего. Ошибиться крайне сложно при написании кода. Первое место. |
|
Недостатки |
Худший результат по памяти. Тут, правда, стоит сказать, что я не знаю, сколько объект типа Dictionary занимает в памяти. Ясно, что методы объекта (код) существуют в памяти скорее всего в одном экземпляре, а вот данные (в том числе private) конечно же существуют в количестве N+1. Но конкретные цифры мне найти не удалось. |
▲ вверх
- Структура DDC
|
Реализация |
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 |
For i = LBound(arrL1) To UBound(arrL1)
For j = LBound(arrL2) To UBound(arrL2)
Set objTemp = New Payload
objTemp.varDouble = arrDouble(j)
objTemp.varLong = arrLong(j)
objTemp.varString = arrString(j)
InsertedDic_Add objRoot, arrL1(i), arrL2(j), objTemp
Next
Next
For i = LBound(arrFindL1) To UBound(arrFindL1)
For j = LBound(arrFindL2) To UBound(arrFindL2)
Set objTemp = InsertedDic_Get(objRoot, arrFindL1(i), arrFindL2(j))
arrTargetDouble(j) = objTemp.varDouble
arrTargetLong(j) = objTemp.varLong
arrTargetString(j) = objTemp.varString
Control = Control + arrTargetLong(j)
Next
Next | |
|
Описание |
То же, что и DDA1V, но вместо одномерного массива используется класс. Класс нужен для того, чтобы отказаться от этого массива и перейти на нечто схожее с UDT, но так как UDT не может быть в качестве полезной нагрузки для item-ов словаря, то приходится городить класс. Впрочем это совершенно не сложно. |
|
Преимущества |
Код выглядит даже лучше, чем у DDA1V. Памяти, скорее всего, тратит столько же (может чуть выше из-за дополнительного пустого класса). Скорость чуть-чуть уступает DDA1V - второе место с разрывом оносительно победителя порядка 3%. |
|
Недостатки |
Только память, а это, учитывая нынешние стандартные конфигурации компьютеров, не такая уж и большая проблема. |
▲ вверх
СРАВНИТЕЛЬНЫЙ АНАЛИЗ
Время, которое показали все структуры в процессе тестирования. Зелёное - лучше, красное - хуже. По скорости работы выявлены 2 практически равноценных победителя: DDA1V и DDC. Как уже было сказано, структура A1UU демонстрирует отличные результаты на малых числах N и имеет отличные шансыулучшить свои характеристики после разработки процедур сортировки массивов, работающих с UDT типами.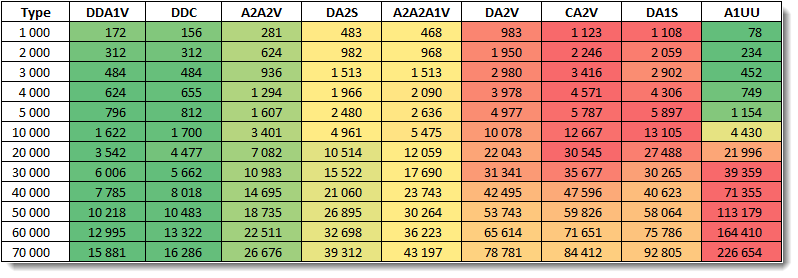
График "скорость - число элементов" на L1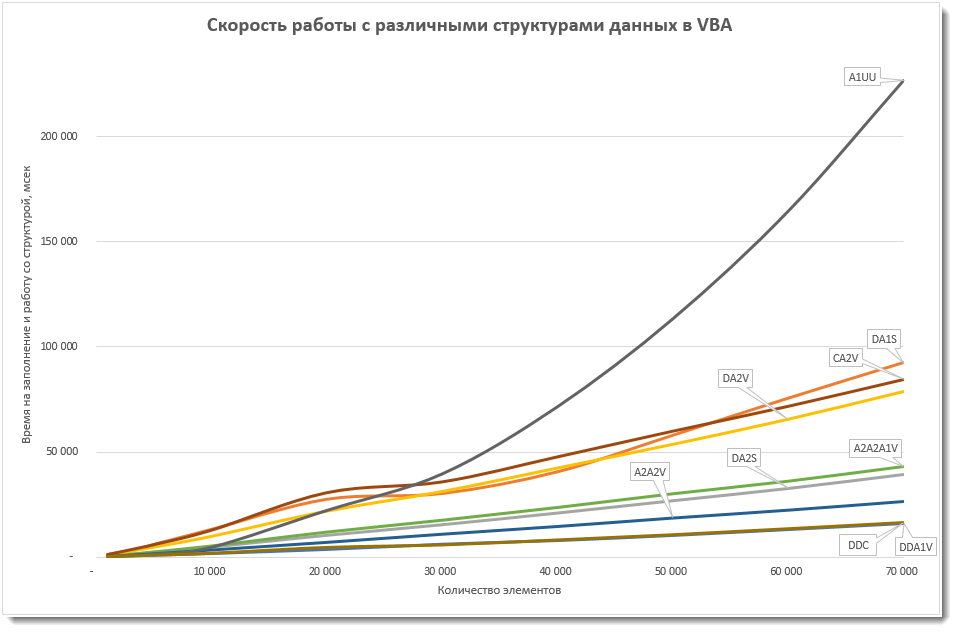
Тот же график, но вблизи малого числа элементов (до 20000)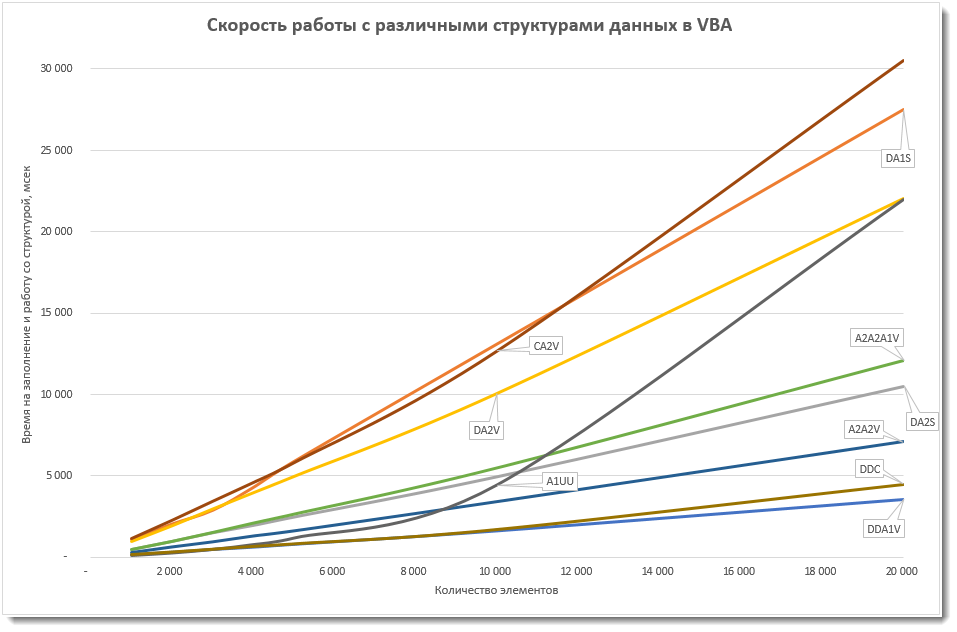
Индикаторы по всем структурам, плюс относительное время и расход памяти.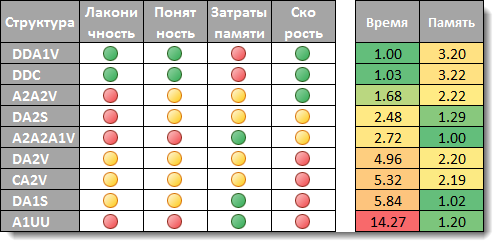
▲ вверх
ФАЙЛ ПРОЕКТА
Скачать
▲ вверх
ИТОГОВЫЕ РЕКОМЕНДАЦИИ
- При росте количества элементов в структурах необходимо либо использовать объект Dictionary, либо массивы совместно с подпрограммами быстрой сортировки и бинарного поиска. Примеры таких подпрограмм вы можете найти в файле примера в модуле QSORT
- Структура, построенная на вложенных друг в друга Dictionary очень эффективна с точки зрения быстродействия. К тому же эта структура сильно расширяет ваши возможности по организации сложных структур данных и, будучи снабжённой подпрограммами по работе с ней, упрощает программирование таких структур.
- Также перспективным направлением является использование массивов с элементами в виде пользовательского типа (UDT), но необходимо написать для неё процедуры сортировки и бинарного поиска.
- Если вы пользуетесь объектами типа Collections, то смело переходите на Dictionary. Рекомендую использовать позднее связывание при создании объектов Dictionary (кстати в моём примере сделано как раз наоборот, поэтому, если у вас не заработали словари, то включите в Tool - References ссылку на Microsoft Scripting Runtime, так как словарь является частью VBScript библиотеки.
- Помните, что победители данного обзора потребляют много оперативной памяти, поэтому хотя бы на пальцах прикидывайте в какие размеры это всё выливается. В файле проекта на листе MemUsage даны мои прикидки.
▲ вверх
Читайте также:
- Работа с объектом Range
- Поиск границ текущей области
- Массивы в VBA
- Автоматическое скрытие/показ столбцов и строк
|
